

Machine Learning – Predict vulnerabilities by examining the words in a URL
Introduction
If you have been in the offensive security field for a while, you start to notice patterns. For example, when looking for certain vulnerabilities such as open redirects, you might have noticed the GET parameter “redirect” shows up a lot. So every time you see that parameter, you test for open redirects. Some people create a list of these types of words and grep for them in URLs, but I wanted to do this a little smarter. Provided you have enough data, you can train a classification algorithm to find these patterns for you, like I have.
Classification Algorithms Basics
Before I go too deep, let's cover some of the basics. According to Google, a classification algorithm is a function that weighs the input features so that the output separates one class into positive values and the other into negative values. Since we are trying to create a classification algorithm based on the words in a URL, we need to use a text based classification algorithm as shown below.
- Naive bayes
- Support vector machines
- Decision tree
- Deep learning
A lot of people ask what's the best classification algorithm and there is no way to tell which one is the best without testing them all. Sometimes Naive Bayes comes out on top and sometimes it doesn’t, it depends on the problem you’re trying to solve.
Metrics
When deciding which algorithm is the best you have to look at the performance metrics as shown below.
- Accuracy – Percentage of text classified correctly
- Precision – The percentage it got right out of the total examples
- Recall – The percentage it predicted out of the total it should of predicted.
Most people get confused about precision and recall so let me make it a little easier to understand. Suppose Jack is predicting whether or not a particular fruit is an apple or an orange. There are 10 apples and 10 oranges. Jack predicts that all 20 fruits are apples. This means for apples Jack has a 100% recall rate because he correctly guessed all the apples but his precision would be at 50% because he guessed half of them incorrectly.
Features
When implementing a classification algorithm you must feed it a list of features. According to Google a feature is an individual measurable property or characteristic of a phenomenon being observed. In our case a feature will be the words in a URL. One of the most common methods for extracting features from text is the “bag of words” approach. Bag of words is just that, its a list words and we simply count how many times each word appears in a URL.
Lets look at the following URLS which contain reflected XSS
- example.com/news/search?q=test&y=1
- somthing.com/music/search?s=millio
As you can see we have the following words:
- news
- search
- q
- y
- music
- s
We then count how many times each word appears as shown below, this is done for every URL in the training set:
[{‘news’:1, ‘search’:1, ‘q’:1, ‘y’:1},{‘music’:1,’search’:1,’s’:1}]
Once you have your features you simply feed that into your classification algorithm and your good to go.
Data Gathering
One of the hardest parts of machine learning is gathering and cleaning the training data. While conducting this experiment I decided to focus on reflected XSS . The first step is to find real life examples of reflected XSS. This was accomplished by using the data from http://xssed.com/ . I created a web scraper and I gathered little over 3,000 reflected XSS examples.

Reflected XSS URLs
Now that I have the vulnerable URLS I need to create an equally sized list of non vulnerable URL. This data was a little easier to locate as there are several sources that collect links. I decided to go with the DMOZ (https://dmoz-odp.org/) . According to Google the DMOZ was a multilingual open-content directory of World Wide Web links owned by AOL. Using this data I took 2,000 links which contain GET parameters and 1,000 which don’t contain any parameters and I marked those as my non vulnerable URLS.
Now that I have my training data I can move on to the next phase which is gathering a list of features from each URL.
Bag of words
Before we can move on to the classification algorithm phase we must gather a list of features from each URL. In our case the features will be the words in a URL. The only words im interested in is the words in the path and the GET parameters. I also had to do a little parsing to split words that are joined together. For instance the words “search_url”, “searchUrl”, and “search-url” all represent the same thing “search url”.
Once we have created our array of words we can use the Sklearn to count how many times each word appears in our URL.
Once that is done we should have a vector representing each URL in our training set. These vectors can then be ingested by our classification algorithms.
Predicting reflected XSS
The last step in this process is to feed our features to the different classification algorithms and see which one performs best.
Naive bayes
Naive bayes is typically the first algorithm people try when doing text based classification. This is because its very fast to train and relatively easy to implement. When testing this classification algorithm I saw an accuracy of 88%.
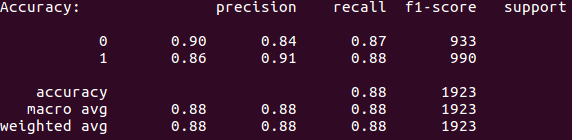
Naive bayes prediction metrics
88% accuracy may seem good but for this experiment I wanted a high precision rate for classifying XSS (1). We can see that that precision rate is only 86%. This means that 14% of the results are false positives. Note the reason why I want a high precision rate when classifying XSS as true is because I plan on using this to examine hundreds of thousands of URLs and I can't afford to be bogged down by false positives.
Decision tree
I originally had high hopes for the decision tree algorithm. I thought it was going to perform the best out of all the algorithms but I was very wrong.
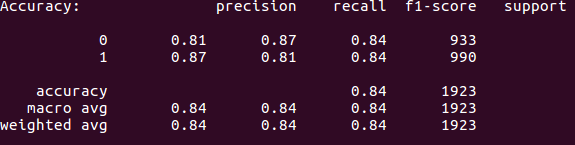
Decision tree prediction metrics
As you can see above the accuracy for this algorithm was only 84%. Although the precision rate rose by 1% everything else seemed to drop.
Support vector machine
I didn’t expect this algorithm to perform well but in the end it beat out the other two.
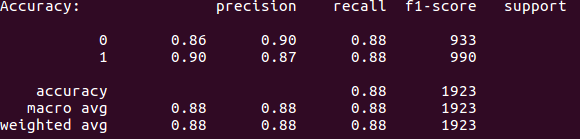
SVM prediction metrics
If you look at the accuracy its the same as Naive bayes 88%. However, the precision went up 4% to 90% which is much better. This means only 10% of our results contain false positives.
Now that I have identified what seems like the best algorithm I need to adjust the parameters of the algorithm to see if I can get better results. This was done programmatically by changing the parameters and finding which combination gives the best results.
After several iterations I determined the following settings to be optimal:
- C = 1.1
- kernel = “linear”
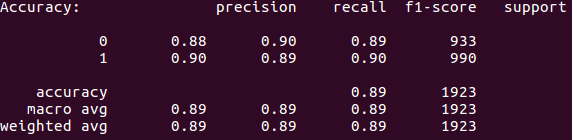
SVM tuned parameters metrics
As you can see the accuracy went up 1% to 89%. This is caused by the algorithm being able to better identify normal URLs as that precision rate went up by 2% to 88%.
Field test
While conducting this in the field I found the results to be highly accurate. I was able to filter a list of 500k URLS to a small list of 3k. While browsing the first 10 results I found 3 cases of reflected XSS and 5 cases of reflected input but it was being filtered. When dealing with big data its almost impossible to test everything, you need to focus on the endpoints that have the most potential. By using a classification algorithm I was able to bubble up the URLS most likely to contain XSS. Literally within 5 min of running the tool I had XSS.
Summary
While conducting this experiment, I have determined that machine learning can be used to predict vulnerabilities simply by looking at the words in a URL. We saw that our algorithm has an 89% accuracy rate. If you are examining a hundred thousand URLs looking for reflected XSS you could feed that list to this classification system to help identify URLS most likely to contain XSS. In the past testing hundreds of thousands of URLs was nearly impossible but we can bypass these limitations by bubbling up the URLs most likely to contain XSS. Note this experiment was only done with reflected XSS but the same can be done with other vulnerabilities such as Sql injection and open redirects.









